
I testi e la SEO: come Google interpreta quello che scriviamo.
Questo capitolo è un’integrazione al “Manuale di copywriting e scrittura per il web” di Alfonso Cannavacciuolo (Hoepli 2018). Si inserisce a pagina 224 e completa il capitolo “SEO copywriting: scrivere per i motori di ricerca”.
Come fa Google a leggere e comprendere i testi che pubblichiamo nel nostro sito web? La prima cosa da dire è che Google non “legge” i contenuti come fa un cervello umano. La lettura è un’attività misteriosa di cui restano ignoti molti meccanismi biologici. Possiamo, quindi, anche affermare che Google “legge” ma deve essere chiaro che non si può paragonare questa attività alla lettura umana. Il motore di ricerca si limita a compiere un’analisi statistica di parole, frasi e significati evidenti o latenti di un testo, cercando di comprendere di cosa tratti un documento.
Questa capacità di Google si è evoluta senza sosta fin dalle prime versioni. In poco meno di 20 anni il motore di ricerca ha sviluppato una straordinaria capacità di comprendere, sempre meglio, quello che abbiamo scritto. Quello che suggeriamo in questo articolo è un percorso tra le diverse tecnologie che Google ha usato negli anni per analizzare i testi. Non è un percorso storico preciso e non cita tutte le tecnologie, gli aggiornamenti e le variazioni che Google ha usato nel corso degli anni. È un riepilogo semplificato utile a chi scrive per il web e ha l’obiettivo di migliorare il posizionamento su un motore di ricerca. Non è un testo per informatici ma per copywriter e redattori.
La fase lessicale
La prima fase di Google possiamo definirla “lessicale” o fase “vocabolario”.
Google scansionava i testi di un sito web alla ricerca delle parole chiave che lo aiutassero a comprendere di cosa parlasse un documento.
Esempio: la Rivoluzione francese
Google vuole trovare tutti i documenti web che contengono la parola chiave “Rivoluzione francese”, indicizzarli e poi restituirli quando qualcuno cerca “Rivoluzione francese”. Se ne va in giro per il web con i suoi crawler e ogni volta che incontra le parole “rivoluzione” e “francese” nello stesso testo inserisce quel documento nell’indice “Rivoluzione francese”. Avremo quindi una matrice di risultati di questo tipo:
| Documento | 1 | 2 | 3 | 4 |
| Rivoluzione | Sì | No | Sì | Sì |
| Francese | Sì | Sì | No | Sì |
Di tutti i documenti che Google ha incontrato, solo il numero 1 e 4 contengono entrambi i termini “rivoluzione” e “francese”. Gli altri due (2 e 3) saranno scartati perché contengono solo 1 dei due termini utili.
Ovviamente con un sistema così semplice, le pagine associate a questa ricerca sono milioni, tutte sostanzialmente sullo stesso piano. Avremo quindi 100.000 pagine che contengono tutte “rivoluzione” e “francese” ma questo non ci è utile per stabilire chi sarà primo nei risultati e chi ultimo.
Ecco quindi altri criteri che Google affiancava alle parole chiave per “provare” a dare una gerarchia coerente ai risultati.
Principio di prossimità
Google dava priorità alle pagine in cui le due parole erano vicine “Rivoluzione francese” rispetto alle pagine in cui “rivoluzione” e “francese” si trovavano in due parti diverse del testo. Il principio è semplice e si comprende con due esempi:
La Rivoluzione francese, nota anche come Prima Rivoluzione francese per distinguerla dalla Rivoluzione di luglio e dalla Rivoluzione francese del 1848, fu un periodo di radicale e a tratti violento sconvolgimento sociale, politico e culturale occorso in Francia tra il 1789 e il 1799, assunto dalla storiografia come lo spartiacque temporale tra l’età moderna e l’età contemporanea. (Wikipedia).
La guerra d’indipendenza americana, nota negli Stati Uniti come Rivoluzione americana fu il conflitto che, tra il 19 aprile 1775 e il 3 settembre 1783, diede il via alle grandi rivoluzioni storiche anticipando di qualche anno quella francese.
Entrambi gli esempi contengono le parole “rivoluzione” e “francese”, ma mentre il primo testo ha un riferimento diretto il secondo no. Non è un modo molto affidabile di classificare un documento, ma è un buon punto di partenza.
Principio di densità
Se in un documento la frase “Rivoluzione francese” è scritta 10 volte, probabilmente tratta quest’argomento in modo più completo di un testo che la contiene 1 o 2 volte.
Principio di condivisione
Se il motore di ricerca non comprende bene quale documento tratta meglio l’argomento “Rivoluzione francese”, lascia fare agli umani. Se due siti parlano dello stesso argomento e il primo riceve 10 link da altri siti e il secondo solo da 3 siti, forse il primo sito è migliore del secondo. In questa fase la quantità dei link è più importante della loro qualità.
Parole sbagliate, sinonimi, plurali e altre perversioni
Come abbiamo detto in precedenza, Google non riconosceva sinonimi e significati delle parole, quindi chi scriveva i testi doveva produrre versioni diverse per i plurali, i sinonimi e le innumerevoli variazioni di parole e frasi, compresi gli errori (mispelling keyword). Questa è la fase in cui un testo posizionato al 1° posto per “cosa vedere a Firenze” non si posizionerà per “cosa visitare a Firenze”.
Esempio
Se l’allora “Strumento per le parole chiave di Google” (External tool) dimostrava che 10.000 persone al mese cercavano “cosa vedere a Firenze”, altre 4.000 “Firenze cosa vedere”, altre 2.000 “cosa visitare a Firenze” e altre 1.000 “Firenze cosa visitare” bisognava produrre 4 contenuti sostanzialmente simili ma variando la parola chiave con cui il testo era ottimizzato.
Questo è il momento in cui singoli siti e l’intero web diventano una discarica di testi duplicati e nasce la figura del SEO copywriter.
Stuffing, vendita di link e altri danni
Questa fase di Google è quella che in assoluto ha prodotto più miti e danni sul lungo periodo.
Il secondo principio (densità) è alla base della famigerata “Keyword density” (densità di keyword) che tanto danno ha fatto ai testi web (e al cervello di chi doveva scriverli!). Si chiedeva a chi scriveva i contenuti di ripetere la parola o frase chiave in una percentuale tra il 3 e 15%, inserendola nel primo paragrafo, mettendola in grassetto e così via.
Il terzo principio è alla base della compravendita di link che ha alterato, e in parte ancora lo fa, i risultati del motore di ricerca. Più link avevi, meglio era, anche se erano da siti di bassa qualità. Quindi la tentazione di comprare e scambiare link da e con altri siti era molto forte: infatti, molti hanno ceduto.
Le persone cercano in modo davvero strano
L’ultimo esempio, quello sulle ricerche su Firenze, ci introduce alla prima evoluzione di Google. Ma prima dobbiamo fare un passo indietro nel 1989, dieci anni prima che Google venisse fondato, quando il web non esisteva ancora. Nei laboratori Bell Lab Susan Dumais e alcuni suoi colleghi stanno studiando un modo per estrarre informazioni da documenti e classificarli. È un problema molto serio e la soluzione sarebbe molto utile.
Molti documenti scientifici che contengono ricerche e dati fondamentali non vengono valorizzati perché non c’è un modo per capire cosa c’è dentro questi documenti. Fino a quel momento la classificazione dei documenti si fa solo analizzando il titolo e la descrizione (vi ricorda qualcosa?). Ma se una parola non è presente in questi due posti, il documento non comparirà nei risultati di ricerca quando un ricercatore la usa. Ma la Dumais e i suoi colleghi hanno anche un obiettivo più ambizioso: recuperare documenti utili per una determinata ricerca, anche se chi sta cercando non usa le parole contenute nei documenti. Il principio da cui partono è che solo il 20% delle persone usa le stesse parole o frasi per descrivere un oggetto e cercare un’informazione. In pratica, su 100 persone che vogliono organizzare un viaggio a Firenze solo 20 cercano “cosa vedere a Firenze”. Le altre 80 useranno molte varianti diverse: “visitare”, “luoghi di interesse”, “da non perdere”, “cose più belle”, “dove andare”, “i migliori posti” e così via. Un altro esempio chiarirà ancora meglio.
Esempio
Un ricercatore sta cercando tutti gli studi sulla correlazione tra disoccupazione e suicidio.
Se cerca nell’archivio digitale usando le parole chiave “disoccupazione” e “suicidio” sicuramente troverà quel che cerca. Ma se usa delle query come “mancanza di lavoro” e “suicidio” troverà solo i documenti che contengono la parola “suicidio” ma non quelle che usano disoccupazione. I risultati, quindi, saranno per lui poco utili.
Quello che i testi non dicono
Il lavoro di Dumais e colleghi è complicato da due cose: la prima è la constatazione di fatto che le lingue sono strumenti complessi. In tutto il mondo si fa largo uso di sinonimi e parole polisemiche (con più significati) che ne fanno variare il significato nel contesto in cui sono usate. “Siamo tutti sulla stessa barca”, in italiano ha un significato letterale (abbiamo preso tutti lo stesso traghetto per andare a Capri) e un significato figurato che intende che “condividiamo tutti la stessa condizione”. Il metodo che vogliono adottare Susan e colleghi è puramente statistico: analizzare milioni di documenti e cercare di comprendere i significati “latenti” o nascosti nelle singole parole e in intere frasi. Con un metodo di questo tipo, una ricerca riuscirebbe a restituire risultati utili anche se chi cerca in un archivio di documenti non usa parole o frasi contenute nel documento. Il nostro ricercatore, quindi, troverebbe i documenti che gli interessano su “disoccupazione” e “suicidio” anche se cerca “conseguenze psicologiche e sociali della perdita del lavoro”. La Dumais e colleghi chiamano questo metodo LSI (non è una droga), cioè Latent Semantic Indexing: indicizzazione basata sui significati latenti. Questo metodo avrebbe migliorato molto la qualità dei risultati di ricerca. Il LSI è diventato poi un brevetto.
Google e i significati nascosti
Se questa tecnologia è disponibile dal 1998, come mai Google non l’ha mai usata limitandosi a classificare i documenti per parole chiave e link in ingresso? Non abbiamo una risposta ma possiamo ipotizzarla.
- Si tratta di un metodo coperto da brevetto. Susan Dumais passò dal Bell Lab a Microsoft, concorrente di Google in più ambiti, compreso il motore di ricerca BING;
- Il brevetto si riferisce a documenti statici, ad esempio libri e ricerche in formato PDF archiviati in modo digitale. Il web invece è un magma in cui ogni giorno vengono creati milioni di nuovi documenti o modificati quelli già esistenti;
- Google non aveva la potenza di calcolo necessaria per applicare questo metodo al web;
- Tutte queste cose insieme.
Dalle parole alle frasi: Google si evolve
Google ha usato il LSI per il suo motore? Pare di no, ma dal 2004 ha iniziato a collezionare brevetti molto simili al LSI in cui il riferimento a questa tecnologia è diretto. Questo insieme di brevetti gira intorno al concetto di “Phrase Index” o “Indice delle frasi”. In pratica Google ha cominciato a classificare i documenti non riferendosi solo alle parole in esse contenute ma anche a frasi che quei documenti potrebbero contenere. Tornando all’esempio sulla “Rivoluzione francese”, analizzando milioni di pagine web Google apprende che dove si parla di “Rivoluzione francese” c’è quasi sempre anche “1789”, “Maria Antonietta”, “ghigliottina”, “Robespierre”, “Presa della Bastiglia”, “Luigi XVI”, “…che mangino le brioche” e così via. Alcune frasi o parole saranno sempre presenti, come la data “14 luglio 1789” mentre “…che mangino le brioche” potrebbe non essere presente in tutti i documenti perché alcuni ritengono che la frase di Maria Antonietta sia un falso storico. Le parole sempre presenti in relazione ad un termine sono definite co-occorrenze.
“14 luglio 1789” è una co-occorrenza di “Rivoluzione francese”. Ognuna di queste co-occorrenze ha un valore statistico molto elevato, altre più basse. Quelle a valore elevato sono un indicatore quasi sicuro che in quella pagina si sta parlando di “Rivoluzione francese”, anche se la frase “Rivoluzione francese” è stata usata poche volte, anche se non è stata usata mai!
Rispetto al sistema delle semplici keyword che abbiamo visto in precedenza, quello a frasi è più complesso ma anche più preciso.
Le keyword sono morte, viva i significati
Grazie a questa evoluzione del motore, le singole parole chiave perdono forza perché è tutto il testo a fornire a Google indicazioni sul contenuto. Non ha più senso imbottire un testo di parole chiave perché se mancano “1789”, “Maria Antonietta”, “ghigliottina”, “Robespierre”, “Presa della Bastiglia”, “Luigi XVI”, “…che mangino le brioche” e così via per Google quel testo non è di qualità.
Grazie all’indicizzazione basata sulle frasi, Google riesce a capire se un testo è di qualità alta, media, bassa o si configura come spam. In base al numero di co-occorrenze presenti in un documento riesce anche a capire se un testo è stato copiato. Con questa evoluzione, un documento creato secondo i principi del keyword stuffing è giudicato come puro spam.
I cluster di parole, frasi sinonimi e super-sinonimi
Come fa Google a sapere quali frasi devono essere associate a un determinato argomento? Lo fa creando sui suoi server milioni di cluster, cioè insiemi in cui a ogni argomento sono associate le co-occorrenze che si aspetta siano presenti in modo significativo. Una cosa che gli riesce abbastanza semplice perché ha aumentato in modo esponenziale la sua potenza di calcolo e le tecnologie di comprensione del testo. Scansiona miliardi di pagine e analizza la bontà dei risultati estraendo dati dai click sui risultati di ricerca e da Analytics. In questi cluster Google inserisce i semplici sinonimi (“cosa vedere a Firenze”, “cosa visitare a Firenze”) ed espressioni che hanno un significato simile: “cose da non perdere”, “cose più importanti”, “luoghi di interesse”, “monumenti più rilevanti”, “cose da fare” e così via. Da questo momento in poi se una pagina è posizionata per la parola chiave principale e più usata “cosa vedere a Firenze” lo sarà quasi sicuramente anche per tutte le co-occorrenze. Le keyword sono definitivamente morte.
Ancora un’evoluzione: Hummingburd, RankBrain e Neural Matching
Dall’aggiornamento Hummingbird in poi (2013), Google si è esclusivamente concentrato sui significati delle parole tralasciando quasi del tutto il sistema basato sulle keyword. A oggi, aprile 2019, il motore funziona con un algoritmo chiamato RankBrain che ha ulteriormente affinato la propria capacità di estrarre i significati evidenti e latenti dei documenti. L’obiettivo è comprendere le intenzioni di ricerca degli utenti restituirgli i risultati più attinenti. Per tornare all’esempio della “Rivoluzione francese”, Google riesce a comprendere che un utente sta cercando informazioni su questo evento anche se fa una ricerca di questo tipo: “evento Francia 1789”.
Ma fin qui è ancora abbastanza semplice: nel cluster di Google relativo alla “Rivoluzione francese” c’è “evento”, c’è “Francia”, c’è “1789” quindi è uno scherzo per RankBrain restituire una pagina sulla “Rivoluzione francese.

Però abbiamo detto che su 100 persone, forse 20-30 usano le stesse parole chiave per cercare un argomento. Le altre useranno espressioni diverse, a volte molto fantasiose, che nulla o poco hanno a che fare con frasi e parole contenute nel cluster. Ed è qui che entra in scena Neural Matching, un algortirmo di Intelligenza Artificiale di Google che cerca di comprendere i significati latenti presenti nelle ricerche delle persone.
Esempio
“Quella cosa che è successa in Francia che hanno tagliato la testa al Re”
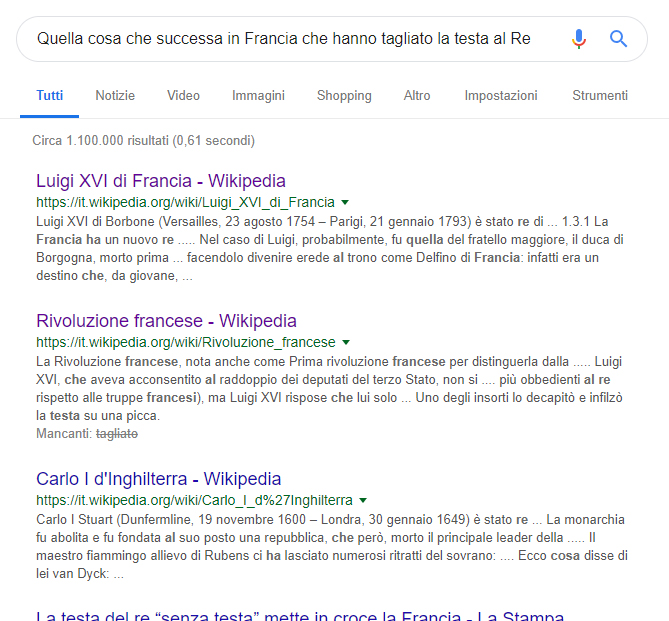
Se RankBrain si occupa di estrarre i concetti evidenti e nascosti nei documenti, Neural Matching fa lo stesso con le ricerche delle persone. Si tratta di una doppia decodifica: Neural Matching cerca di capire cosa stanno cercando le persone e RankBrain restituisce il risultato che ritiene più giusto.
Esiste ancora il SEO copywriter?
Non più. Quando Google funzionava esclusivamente sulle keyword, saper ottimizzare i testi con le parole chiave era una competenza, non difficile da ottenere ma in parte apprezzata dal mercato. Ora che le keyword non servono più a nulla, sono altre le competenze che deve avere chi scrive per il web con l’obiettivo di posizionarsi.
- Studiare bene l’argomento di cui bisogna scrivere e tutte le eventuali correlazioni tra argomenti; Non possiamo sapere cosa contengono i cluster di Google, ma seguendo una regola di buon senso possiamo prevedere cosa si aspetti da noi;
- Avere un vocabolario ampio e articolato;
- Avere un processo editoriale di qualità: progettazione, scrittura, revisione, pubblicazione;
- Strutturare un testo in modo coerente, omogeneo, logico: questo permette di far comprendere a Google di cosa stiamo parlando e dare rilevanza al nostro contenuto.
Servono ancora Title, H1, H2 e altri elementi SEO del testo.
Sempre meno. Google ha la capacità di comprendere un testo al di là dell’ottimizzazione dei singoli Tag Html. Oggi title e H1 hanno ancora qualche rilevanza, ma durerà ancora poco. Continueranno a servire agli utenti per comprendere velocemente cosa contiene una pagina (title e H1) e aiutare la leggibilità del testo (H1-H6). Tra poco tempo, al massimo 1 anno, la forza di posizionamento di un testo dipenderà esclusivamente dal testo stesso. Google ci sta dicendo una cosa semplice e diretta: imparate a scrivere. Se non sapete farlo, affidatevi a qualcuno che lo sappia fare per mestiere. Il tempo delle parole chiave è finito.
Come si diventa SEO copywriter oggi?
Con queste evoluzioni di Google non c’è più differenza tra la qualità di scrittura di un SEO copywriter e un redattore tradizionale che scrive non curandosi del posizionamento, anzi. Il secondo è avvantaggiato perché riesce a trattare un argomento nella sua complessità e interezza senza dare peso alle parole chiave. Il tempo dell’improvvisazione è finito: tutti possono ottimizzare un testo con le keyword ma scrivere in modo preciso e completo di un argomento richiede capacità di lettura, scrittura, allenamento. E tanta, davvero tanta, cultura.
